Harnessing Best-Effort Computing to Enable Dynamic Artificial Life Simulations at Scale
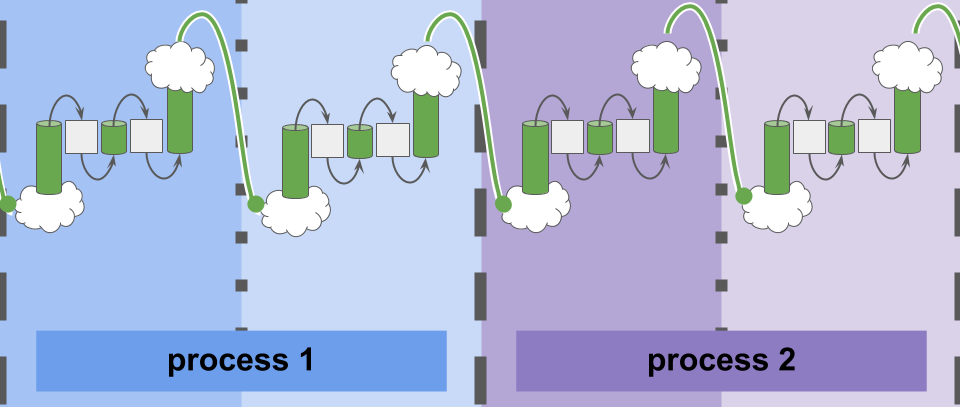 Cartoon illustration of communication between simulation elements in experiment with Conduit software.
Cartoon illustration of communication between simulation elements in experiment with Conduit software.
The parallel and distributed processing capacity of high-performance computing (HPC) clusters continues to grow rapidly and enable profound scientific and industrial innovations. These advances in hardware capacity and economy afford great opportunity, but also pose a serious challenge: developing approaches to effectively harness it.
Software and hardware that relaxes guarantees of correctness and determinism — a so-called ``best-effort model’’ — have been shown to improve speed. This work distills best-effort communication from the larger issue of best-effort computing. Specifically, we investigate the implications of relaxing synchronization and message delivery requirements. Such a best-effort approach meets the challenges of heterogenous, varying (i.e., due to power management), and generally lower communication bandwidth (relative to compute) expected on future HPC hardware. Notably, such a model presents the possibility of runtime adaptation to effectively utilize available resources given the particular ratio of compute and communication capability at any one moment in any one rack.
Complex biological organisms exhibit characteristic best-effort properties: trillions of cells interact asynchronously while overcoming all but the most extreme failures in a noisy world. As such, bio-inspired algorithms present strong potential to benefit from best-effort communication strategies.
Much exciting work on best-effort computing has incorporated bespoke experimental hardware. However, existing software libraries for traditional HPC hardware do not typically explicitly expose a convenient best-effort communication interface for such work. This work introduces the Conduit library, which facilitates best-effort communication between parallel and distributed processes on existing, commercially-available hardware.
Publications & Software
View at Publisher
| Authors | Matthew Andres Moreno, Connor Yang, Emily Dolson, Luis Zaman |
| Date | May 6th, 2024 |
| DOI | 10.1145/3638530.3664090 |
| Venue | The Genetic and Evolutionary Computation Conference |
Abstract
Emerging ML/AI hardware accelerators, like the 850,000 processor Cerebras Wafer-Scale Engine (WSE), hold great promise to scale up the capabilities of evolutionary computation. However, challenges remain in maintaining visibility into underlying evolutionary processes while efficiently utilizing these platforms’ large processor counts. Here, we focus on the problem of extracting phylogenetic information from digital evolution on the WSE platform. We present a tracking-enabled asynchronous island-based genetic algorithm (GA) framework for WSE hardware. Emulated and on-hardware GA benchmarks with a simple tracking-enabled agent model clock upwards of 1 million generations a minute for population sizes reaching 16 million. This pace enables quadrillions of evaluations a day. We validate phylogenetic reconstructions from these trials and demonstrate their suitability for inference of underlying evolutionary conditions. In particular, we demonstrate extraction of clear phylometric signals that differentiate wafer-scale runs with adaptive dynamics enabled versus disabled. Together, these benchmark and validation trials reflect strong potential for highly scalable evolutionary computation that is both efficient and observable. Kernel code implementing the island-model GA supports drop-in customization to support any fixed-length genome content and fitness criteria, allowing it to be leveraged to advance research interests across the community.
BibTeX
@inproceedings{moreno2024trackable_gecco,
author = {Matthew Andres Moreno and Connor Yang and Emily Dolson and Luis Zaman},
title = {Trackable Island-model Genetic Algorithms at Wafer Scale},
pages = {101-102},
isbn = {9798400704956},
year = {2024},
publisher= {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3638530.3664090},
doi = {10.1145/3638530.3664090},
booktitle= {Proceedings of the Genetic and Evolutionary Computation Conference Companion},
numpages = {2},
location = {Melbourne, VIC, Australia},
series = {GECCO '24}
}
Citation
Matthew Andres Moreno, Connor Yang, Emily Dolson, and Luis Zaman. 2024. Trackable Island-model Genetic Algorithms at Wafer Scale. In Proceedings of the Companion Conference on Genetic and Evolutionary Computation (GECCO ‘24 Companion). Association for Computing Machinery, New York, NY, USA. https://doi.org/10.1145/3638530.3664090
Supporting Materials
View at Publisher
| Authors | Matthew Andres Moreno, Connor Yang, Emily Dolson, Luis Zaman |
| Date | April 16th, 2024 |
| DOI | 10.1162/isal_a_00830 |
| Venue | The 2024 Conference on Artificial Life |
Abstract
Continuing improvements in computing hardware are poised to transform capabilities for in silico modeling of cross-scale phenomena underlying major open questions in evolutionary biology and artificial life, such as transitions in individuality, eco-evolutionary dynamics, and rare evolutionary events. Emerging ML/AI-oriented hardware accelerators, like the 850,000 processor Cerebras Wafer Scale Engine (WSE), hold particular promise. However, practical challenges remain in conducting informative evolution experiments that efficiently utilize these platforms’ large processor counts. Here, we focus on the problem of extracting phylogenetic information from agent-based evolution on the WSE platform. This goal drove significant refinements to decentralized in silico phylogenetic tracking, reported here. These improvements yield order-of-magnitude performance improvements. We also present an asynchronous island-based genetic algorithm (GA) framework for WSE hardware. Emulated and on-hardware GA benchmarks with a simple tracking-enabled agent model clock upwards of 1 million generations a minute for population sizes reaching 16 million agents. We validate phylogenetic reconstructions from these trials and demonstrate their suitability for inference of underlying evolutionary conditions. In particular, we demonstrate extraction, from wafer-scale simulation, of clear phylometric signals that differentiate runs with adaptive dynamics enabled versus disabled. Together, these benchmark and validation trials reflect strong potential for highly scalable agent-based evolution simulation that is both efficient and observable. Developed capabilities will bring entirely new classes of previously intractable research questions within reach, benefiting further explorations within the evolutionary biology and artificial life communities across a variety of emerging high-performance computing platforms.
BibTeX
@inproceedings{moreno2024trackable,
author = {Matthew Andres Moreno and Connor Yang and Emily Dolson and Luis Zaman},
title = {Trackable Agent-based Evolution Models at Wafer Scale},
booktitle = {The 2024 Conference on Artificial Life},
collection = {ALIFE 2024},
publisher = {MIT Press},
year = {2024},
month = {07},
doi={10.1162/isal_a_00830},
url={https://doi.org/10.1162/isal_a_00830},
numpages={12},
pages={87-98},
}
Citation
Moreno, M. A., Yang, C., Dolson, E., & Zaman, L. (2024). Trackable Agent-based Evolution Models at Wafer Scale. In The 2024 Conference on Artificial Life. MIT Press. https://doi.org/10.1162/isal_a_00830
View at Publisher
| Authors | Matthew Andres Moreno, Charles Ofria |
| Date | November 23rd, 2022 |
| DOI | 10.48550/arXiv.2211.10897 |
| Venue | arXiv |
Abstract
Here, we test the performance and scalability of fully-asynchronous, best-effort communication on existing, commercially-available HPC hardware.
A first set of experiments tested whether best-effort communication strategies can benefit performance compared to the traditional perfect communication model. At high CPU counts, best-effort communication improved both the number of computational steps executed per unit time and the solution quality achieved within a fixed-duration run window.
Under the best-effort model, characterizing the distribution of quality of service across processing components and over time is critical to understanding the actual computation being performed. Additionally, a complete picture of scalability under the best-effort model requires analysis of how such quality of service fares at scale. To answer these questions, we designed and measured a suite of quality of service metrics: simulation update period, message latency, message delivery failure rate, and message delivery coagulation. Under a lower communication-intensivity benchmark parameterization, we found that median values for all quality of service metrics were stable when scaling from 64 to 256 process. Under maximal communication intensivity, we found only minor – and, in most cases, nil – degradation in median quality of service.
In an additional set of experiments, we tested the effect of an apparently faulty compute node on performance and quality of service. Despite extreme quality of service degradation among that node and its clique, median performance and quality of service remained stable.
BibTeX
@misc{moreno2022best,
doi = {10.48550/ARXIV.2211.10897},
url = {https://arxiv.org/abs/2211.10897},
author = {Moreno, Matthew Andres and Ofria, Charles},
keywords = {Distributed, Parallel, and Cluster Computing (cs.DC), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Best-Effort Communication Improves Performance and Scales Robustly on Conventional Hardware},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
Citation
Moreno, M. A., & Ofria, C. (2022). Best-Effort Communication Improves Performance and Scales Robustly on Conventional Hardware. arXiv preprint arXiv:2211.10897.
Supporting Materials
View at Publisher
| Authors | Matthew Andres Moreno, Santiago Rodriguez Papa, Charles Ofria |
| Date | May 21st, 2021 |
| DOI | 10.1145/3449726.3463205 |
| Venue | ACM Workshop on Parallel and Distributed Evolutionary Inspired Methods |
Abstract
Developing software to effectively take advantage of growth in parallel and distributed processing capacity poses significant challenges. Traditional programming techniques allow a user to assume that execution, message passing, and memory are always kept synchronized. However, maintaining this consistency becomes increasingly costly at scale. One proposed strategy is “best-effort computing”, which relaxes synchronization and hardware reliability requirements, accepting nondeterminism in exchange for efficiency. Although many programming languages and frameworks aim to facilitate software development for high performance applications, existing tools do not directly provide a prepackaged best-effort interface. The Conduit C++ Library aims to provide such an interface for convenient implementation of software that uses best-effort inter-thread and inter-process communication. Here, we describe the motivation, objectives, design, and implementation of the library. Benchmarks on a communication-intensive graph coloring problem and a compute-intensive digital evolution simulation show that Conduit’s best-effort model can improve scaling efficiency and solution quality, particularly in a distributed, multi-node context.
BibTeX
@inproceedings{moreno2021conduit,
author = {Moreno, Matthew Andres and Rodriguez Papa, Santiago and Ofria, Charles},
title = {Conduit: A C++ Library for Best-Effort High Performance Computing},
year = {2021},
isbn = {9781450383516},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3449726.3463205},
doi = {10.1145/3449726.3463205},
booktitle = {Proceedings of the Genetic and Evolutionary Computation Conference Companion},
pages = {1795–1800},
numpages = {6},
keywords = {high performance computing, best-effort computing},
location = {Lille, France},
series = {GECCO '21}
}
Citation
Matthew Andres Moreno, Santiago {Rodriguez Papa}, and Charles Ofria. 2021. Conduit: a C++ library for best-effort high performance computing. In Proceedings of the Genetic and Evolutionary Computation Conference Companion (GECCO ‘21). Association for Computing Machinery, New York, NY, USA, 1795–1800. https://doi.org/10.1145/3449726.3463205
View at Publisher
| Authors | Matthew Andres Moreno, Santiago Rodriguez Papa, Charles Ofria |
| Date | March 12th, 2021 |
| Venue | The 6th International Workshop on Modeling and Simulation of and by Parallel and Distributed Systems (MSPDS 2020) |
Abstract
Developing software to effectively take advantage of growth in parallel and distributed processing capacity poses significant challenges. Best-effort computing models, which relax synchronization requirements, have been proposed as a strategy to overcome challenges harness high performance computing at extreme scale. Although many programming languages and frameworks aim to facilitate software development for high performance applications, existing prevalent tools do not expose an explicit best-effort interface. The Conduit C++ Library aims to provide a convenient interface for best-effort inter-thread and inter-process communication. Here, we describe the motivation, objectives, design, and implementation of the library.
BibTeX
@inproceedings{moreno2021conduit_hpcs,
author = {Moreno, Matthew Andres and Rodriguez Papa, Santiago and Ofria, Charles},
title = {Conduit: A C++ Library for Best-Effort High Performance Computing},
year = {2021},
booktitle = {The 6th International Workshop on Modeling and Simulation of and by Parallel and Distributed Systems (MSPDS 2020)},
numpages = {2},
keywords = {high performance computing, best-effort computing},
location = {Barcelona, Sapin},
series = {HPCS 2021}
}
Citation
Matthew Andres Moreno, Santiago Rodriguez Papa and Charles Ofria. 2021. Conduit: A C++ Library for Best-Effort High Performance Computing. MSPDS 2020: The 6th International Workshop on Modeling and Simulation of and by Parallel and Distributed Systems.
Supporting Materials
| Authors | Matthew Andres Moreno, Santiago Rodriguez Papa, Charles Ofria |
| Date | January 1st, 2020 |
| Venue | header-only C++ library |
C++ library that wraps intra-thread, inter-thread, and inter-process communication in a uniform, modular, object-oriented interface, with a focus on asynchronous high-performance computing applications.
BibTeX
@inproceedings{moreno2021conduit,
author = {Moreno, Matthew Andres and Rodriguez Papa, Santiago and Ofria, Charles},
title = {Conduit: A C++ Library for Best-Effort High Performance Computing},
year = {2021},
isbn = {9781450383516},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3449726.3463205},
doi = {10.1145/3449726.3463205},
booktitle = {Proceedings of the Genetic and Evolutionary Computation Conference Companion},
pages = {1795–1800},
numpages = {6},
keywords = {high performance computing, best-effort computing},
location = {Lille, France},
series = {GECCO '21}
}
Citation
Matthew Andres Moreno, Santiago Rodriguez Papa, and Charles Ofria. 2021. Conduit: a C++ library for best-effort high performance computing. In Proceedings of the Genetic and Evolutionary Computation Conference Companion (GECCO ‘21). Association for Computing Machinery, New York, NY, USA, 1795–1800. https://doi.org/10.1145/3449726.3463205